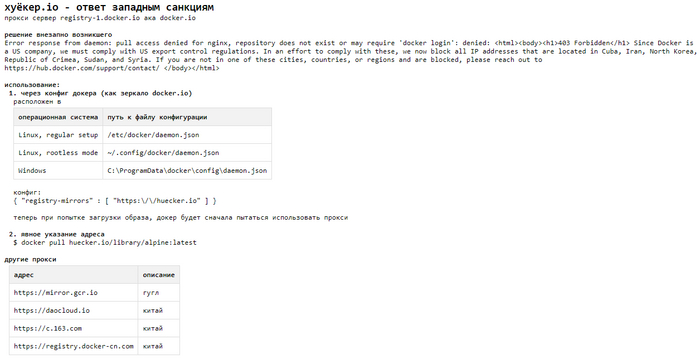
Сегодня утром при попытке создать образ возникла проблема к попытке подключения к dockerhub. Причем эти люди с альтернативными сексуальными предпочтениями даже не указали Россию в список стран под запретом:
403 Forbidden Since Docker is a US company, we must comply with US export control regulations. In an effort to comply with these, we now block all IP addresses that are located in Cuba, Iran, North Korea, Republic of Crimea, Sudan, and Syria. If you are not in one of these cities, countries, or regions and are blocked, please reach out to https://hub.docker.com/support/contact/
Думаю, для тех кто знаком с данным сервисом понимают последствия.
Решение появилось достаточно быстро - https://huecker.io/. Также при работе через VPN проблем также не возникает
Я обычный программист город Тверь, никогда не проектировал софт и не был архитектором.
Но очень горю желанием сделать наконец уже свой серьезный проект.
Много раз пытался делать разные проекты, и пришел к выводу, что мне очень не хватает компетенции в сфере планирования и проектирования. Пока я знаю, что и как делать, то проект растет. Но без четкого плана на голом энтузиазме я держусь недолго.
Я надеюсь, что здесь есть люди, которые в этом разбираются, и которые были бы рады помочь неофиту.
В общем, я пришел к выводу, что мне нужно перед любой разработкой проследовать по такому плану:
Составить документы по 5 конкурентам, в которых перечислить:
- Функционал детально
- Страницы, пункты меню
- Entities и их поля
- Взаимосвязи, сценарии
- Какие есть роли
- Функционал по разным ролям
- Что редактируется, когда редактируется, кем редактируется
Смержить эти документы и получить MVP, в котором будет прописан функционал, entities and fields, взаимосвязи и сценарии, роли, функционал по ролям и т.д.
На основе выше полученного спроектировать базу данных.
Потом разбить на задачи по страницам, по сценариям, по ролям.
Детально прописать задачи, какие поля на странице, какие placeholders, опции селектов.
Заказать реализацию дизайна для каждой задачи.
Начать реализацию кода.
Подскажите пожалуйста, все ли я правильно понял, и может быть я что-то упустил?
Всем привет, в последние годы я исследую Искусственный Интеллект, мой контент об этом можно найти на канале Ruslan Dev на YouTube. В этой статье я расскажу о том, как я сделал файнтюнинг Llama 3 70B - лучшей базовой модели на сегодняшний день. Я обучал модель на мультиязычном датасете Tagengo, в котором есть русскоязычная выборка.
Очевидно, обучение такой модели требует серьезных вычислительных мощностей, поэтому полного цикла на 3-4 эпохи я делать не стал. Я рассчитывал потратить пять-десять GPU-часов, чтобы проверить мой код для файнтюнинга на работоспособность, посмотреть метрики обучения, запустить инференс модели и оценить первые результаты.
Моей второй целью была квантизация обученной модели и сохранение в формате GGUF. Этот формат позволяет запустить Большую Языковую Модель (LLM) на любом компьютере с достаточно мощным процессором.
Базовая модель, которую я файнтюнил -unsloth/llama-3-70b-bnb-4bit. Cначала я проверил, как эта модель справляется с русскоязычным промптом, задав ей вопрос - "Из чего состоит нейронная сеть?"
Очевидно, что базовая модель не обучена следовать инструкциям. Она просто повторяла мой вопрос, итерация за итерацией, пока генерация не достигла максимальной заданной длины. Я рассчитывал на то, что после файнтюнинга модель будет следовать инструкциям на русском языке.
Сначала я собирался обучать на нескольких видеокартах параллельно и выбрал два GPU A100c NvLink.
Однако, я не учел тот факт, что библиотека unsloth, которую я использую в моем фреймворке, еще не поддерживает model parallelism, а это серьезное ограничение. В их дискорде нашел пост, что в ближайшее время обучение на нескольких GPU станет возможным. Если этого не случится, мне придется искать альтернативные пути.
Поскольку файнтюнинг базовой модели Llama 70B c квантизацией в 4 bit на 3 эпохи на одном A100 требует порядка 5 дней, мне пришлось сократить количество шагов обучения.
Также я решил перейти на другую видеокарту - H100, самую мощную из того что есть.
Настройка рабочего окружения у меня довольно простая. Мне нужен только python >= 3.9, а затем клонирую свой фреймворк gptchain с github:
На странице датасета заявлено, что "Tagengo - самый большой в мире мультиязычный датасет высокого качества". 78 тысяч примеров диалога на разных языках, включая русский. Здесь есть серьезная выборка на русском - 8 тысяч строк.
Я обучил модель на 2,400 шагов, на это ушло 7 часов на H100.
Если использовать A100, по моим расчетам, потребовалось бы примерно 10 часов.
Я запустил файнтюнинг на Виртуальной Машине в бэкграунд-процессе. Для этого я воспользовался systemd, стандартным способом создания фоновых процессов (демонов) в Linux.
Как настроить фоновый процесс для файнтюнинга через systemd:
Я создал файл gptchain.service в /etc/systemd/system. В него вставил вот такую конфигурацию:
Здесь главное - команда gptchain.py train, которая запускает файнтюнинг модели.
А теперь нужно выполнить:
sudo systemctl daemon-reload
sudo systemctl start gptchain
И все, остается ждать завершения файнтюнинга, но метрики вроде Train Loss хотелось бы как-то отслеживать. Самое простое - посмотреть логи процесса:
journalctl -u gptchain.service
Чтобы иметь возможность нормально наблюдать метрики, лучше, конечно, использовать wandb или tensorboard.
В этот раз я использовал wandb - просто указал ключ доступа в переменной WANDB_API_KEY в файле .env. Мой процесс подключается к wandb автоматически и экспортирует метрики в реальном времени.
Внутри команды train (вкратце) происходит следующее:
К базовой модели применяется LoRA (Low Rank Adaptation), метод, позволяющий файнтюнить параметры более эффективно - исходная матрица параметров оставляется неизменной ( "замораживается"). В процессе обучения изменяется представление параметров модели в виде двух матриц более низкой размерности. Реализация LoRA, с которой мы обычно имеем дело, работая на стеке Huggingface Transformers (как и в данном случае) - через библиотеку peft.
Дальше происходит загрузка датасета и приведение к нужной структуре. Данные в Tagengo представлены в виде массивов json, какие принимает и возвращает OpenAI API. Чтобы использовать эти данные для файнтюнинга, я сконвертировал их в формат ChatML. У библиотеки Unsloth есть хорошая поддержка СhatML, что мне очень помогло конвертировать данные из вот этого:
[
{
"from": "human",
"value": "The user’s message goes here"
},
{
"from": "gpt",
"value": ""
}
]
Вот в это:
<|im_start|>user
The user’s message goes here
<|im_end|>
<|im_start|>assistant
Следующее, что происходит в моем коде - конфигурируется экземпляр Supervised Fine-tuning Trainer (SFTTrainer) - класса, предоставленного библиотекой trl. В нем задаются параметры файнтюнинга.
Основные из них:
learning_rate: 2e-4
seed: 3407
gradient_accumulation_steps: 4
per_device_train_batch_size: 2
optimizer: adamw_8bit
lr_scheduler_type: linear
warmup_steps: 5
max_steps: 2400
weight_decay: 0.01
Через семь часов файнтюнинг завершился. Я убедился, что Train Loss медленно, но верно сходится. Хотелось бы обучить на несколько полных эпох, но, как я уже говорил, надо значительно больше GPU часов. Обучать нужно минимум на 2, а лучше на 4 видеокартах параллельно.
Затем я проверил, начала ли Llama следовать инструкциям на русском языке:
-q '[{"from": "human", "value": "Из чего состоит нейронная сеть?"}]' \
--chatml true
Да, начала - вместо бессмысленных повторений я получил правильный, очень подробный ответ на вопрос "Из чего состоит нейронная сеть?" Рекомендую посмотретьвидео, чтобы оценить качество ответа и скорость инференса Llama 3 70B наH100.
Стиль ответа напоминает GPT-4, это длинный детализированный текст. Неудивительно, так как датасет tagengo включает именно ответы GPT-4.
Затем я выполнил квантизацию модели и сконвертировал ее в формат GGUF, чтобы ее можно было запускать без GPU, на обычном процессоре.
Для этого в моем фреймворке есть консольная команда quant. Среди прочих аргументов она принимает метод квантизации. В интерфейсе llama.cpp, который используется под капотом, есть также полезная команда quantize --help, которая покажет много полезной информации по методам квантизации, в том числе какие из них рекомендуются в плане баланса качества модели, скорости инференса и размера файла. Я воспользовался методом q4_k_m:
Для Llama 3 70B непосредственно квантизация занимает примерно полчаса, перед этим еще произойдет сборка llama.cpp из C++ исходников, что необходимо для конвертации весов модели в GGUF формат.
В итоге вы получите файл gguf в папке quants, его можно запустить с помощью llama.cpp.
Я задал модели тот же вопрос "Из чего состоит нейронная сеть?", и модель начинала генерировать просто completion - завершила фразу, выдала в конце токен end-of-text и остановилась.
Это потому, что я не задал формат промпта. Здесь ведь нет автоматической конвертации инпута в формат СhatML, которую мне обеспечивал Unsloth при инференсе несжатой модели.
-p "<|im_start|>user \nИз чего состоит нейронная сеть?<|im_end|>"
Модель на этот раз поняла, что от нее хотят. Она сгенерировала ответ в нужном формате.
Это такой же развернутый ответ в том же стиле, что у несжатой модели. Но инференс GGUF значительно медленнее, чем на GPU. Зато вы можете запустить этот файл на любом компьютере, лишь бы хватило мощности CPU, иначе инференс будет длиться вечность.
Однако ближе к концу ответа модель стала генерировать странную последовательность обратных слэшей и других символов. У несжатой модели такого дефекта не было. Возможно, если бы файнтюнинг был проведен полностью, эта проблема бы не возникла.
Тем не менее, в целом мне понравилось качество ответов обеих моделей - с квантизацией и без. Я бы хотел протестировать свою модель на разных бенчмарках, например MT-Bench, в особенности меня интересуют результаты для русского языка. Это, вероятно, тема для новой статьи. А пока я рекомендую посмотреть видео о том, как происходил файнтюнинг, описанный в этой статье.
Постараюсь ужать многолетний опыт изучения навыков в одну малюсенькую статейку. Расскажу , как на практике освоить набор навыков любого размера, включая все необходимое, чтобы получить первую работу в IT. Объясню пошагово, как создать и придерживаться очень практичного и эффективного индивидуального плана обучения, по которому я сам занимался, в результате чего из полного чайника без диплома и платных курсов за пол года смог влететь в разработку на высококонкурентном рынке с 1000+ откликов на вакансию во времена массовых увольнений сразу в топовую IT‑компанию без связей, накрутки опыта и ментора и даже успешно пройти там испыталку, ведь план обучения позволил накопить багаж полезных знаний.
Правильный план обучения — это 70% получения работы. По этому плану ты сможешь освоить программирование без покупки курсов, то есть стать программистом бесплатно. Да и любой другой скилл или профессию тоже сможешь быстро и бесплатно получить, что сейчас особенно актуально с этим ИИ. Гарантирую, что по этому плану за короткий срок ты добьёшься больших результатов, а это автоматически значит, что потребуется тяжелая работа с твоей стороны. В конце статьи также будет секретный ингредиент, о котором никто не говорит и который может сделать процесс твоего обучения чуть ли не вдвое более эффективным. Ещё я приведу пример реального плана обучения и объясню, почему каждый его пункт настолько логичен, что ты просто не сможешь ему не придерживаться. Цель плана ‑получить максимальный результат при минимальных затратах времени и сил.
Почему вообще нужно составлять план обучения самому? Нельзя что ли чей‑то готовый роудмап найти или курс купить, где план уже есть? Составлять план самому — суперважно, потому что когда ты понимаешь, что и зачем в нём делается и насколько это действительно эффективно, то и придерживаться этого плана становится гораздо проще, так как мотивация просто не пропадает. Да и если что‑то в плане не работает, можно всегда его подкорректировать, это же твой собственный план. Поняв, что работает, а что нет, ты в будущем сможешь создавать эффективные планы для освоения любых навыков, в том числе для выхода в синьеры‑помидоры, т.к. одного волшебного курса по становлению синьером вроде еще никто не запилил. Единственный доступный вариант — самому грамотно выстроить процесс обучения, чтобы результат был максимальным.
Самое простое в создании плана обучения — определить, какие именно навыки нужно приобрести. Для этого можно провести небольшое исследование и посмотреть требования к кандидатам на вакансии твоей будущей специализации. Учти, что учить стоит только то, что так или иначе повышает твой доход. Это значит, что стоит фокусироваться только на необходимых для получения работы знаниях и навыках, отметая все лишнее, в обратном случае будет сложно конкурировать с другими челами. Отметать, нужно, например, ассемблер или внутреннее устройство ОС, которые знать не обязательно и даже вредно. Некоторые говорят, что нужно же знать эту «базу», но объяснить зачем толком не могут. Выбрав необходимые для работы скиллы, нужно понять самое главное — как эффективно учиться. Это будет основой твоего плана обучения. Многим кажется, что они и так умеют учиться, но, если бы все это умели, никто бы не мучился с получением первой работы в IT, так как количество твоих навыков прямо пропорционально шансу получения работы. Основы обучения, о которых пойдет речь, очень практичны и я их сам уже много лет использую:
Практика
Практика — это самое важное. Хорошее соотношение практики и теории при обучении для новичков — 80% на 20%. То есть, если ты посмотрел 8-минутное видео, например, про декораторы в Python, то в IDE надо потом не меньше получаса с ними поиграться. Большинство людей практику скипают, потому что это гораздо сложнее, чем видосы смотреть. В итоге они застревают в так называемом «tutorial hell», то есть смотрят много контента, но на практике ничего сделать не могут, поэтому их навыки не развиваются.
Интервальные повторения
Непонимание интервальных повторений — причина, по которой 95% вкатунов сливаются в первые месяцы. Работает это так: когда ты что‑то учишь впервые,то это запоминается на пару дней. Если тему повторить через 2 дня после изучения, то запомнится она уже на 4 дня. Повторишь еще раз к концу четвертого дня — тема запомнится уже на целых 8 дней. Потом на 16, 32 и так далее. Бытует мнение, что в итоге доходишь до момента, где выученное запоминаешь на вечно, так, что повторять тему больше не надо. Хоть это и кажется нереальным, это действительно так работает, однако тому есть научное объяснение: допустим, ты повторяешь тему в девятый раз и теперь будешь помнить её ещё целый год. Если вовсе перестать ее повторять, то всё равно имеется почти 100% шанс того, что за этот год в работе ты случайно столкнёшься с этой темой и тебе придётся естественным образом достать информацию из мозга, просто чтобы совершить намеченное действие. Таким образом тема повторится сама по себе и еще лучше закрепится в голове. Затем вероятность того, чтобы ты случайно встретишь эту тему в работе за следующие 2 года возрастает еще сильнее и тем самым цикл замыкается, в результате чего ты запоминаешь тему как бы «на вечно»
Вот что происходит с теми, кто не применяет интервальные повторения: Допустим, им нужно выучить 15 ключевых навыков или больших тем для получения работы. Большинство новичков учат первые 9 навыков, потом приступают к 10-му, одновременно забывая первый. Потом учат 11-й, параллельно забывая второй и так далее. Они застревают на 9 из 15 необходимых тем или навыков и несмотря на все усилия, не могут преодолеть этот барьер, ведь скорость забывания слишком высока. Причина в том, что они не используют интервальные повторения. Они учат что‑то один раз и двигаются дальше, поэтому постоянно забывают то, что учили ранее. Но если использовать интервальные повторения и регулярно повторять пройденные темы, то можно выучить бесконечное количество навыков и тем, не забывая их. Самое важное в том, что интервальные повторения буквально гарантируют, что ты найдешь работу, потому что они обеспечивают постоянное расширение твоего набора навыков без его уменьшения. Это продолжается вплоть до момента, когда твой набор навыков достигает критической массы и ты становишься настолько хорош, что твой будущий работодатель уже просто не в состоянии игнорировать тебя (естественно надо еще получить навык поиска работы, но это уже отдельная тема).
Для внедрения интервальных повторений можно использовать карточки Anki. Карточки Anki — это приложение, используемое для обучения и запоминания. На лицевой стороне каждой карточки находится вопрос, на оборотной стороне — ответ. Карточки становятся доступны ровно в тот момент времени, в который это необходимо для наилучшего применения принципа интервальных повторений. Эти же карточки включают в себя и не менее важный принцип — принцип активного вспоминания.
Активное вспоминание
Активное вспоминание сводится к следующему высказыванию: твой мозг запоминает информацию не когда ты её откуда‑то получаешь, а именно когда извлекаешь её из мозга. Если, ты, например, прочтешь эту статью и сразу переключишься на следующую, то будешь что‑то помнить из этой статьи еще в течение примерно одного часа. Но если при прочтении статьи периодически останавливаться и объяснять себе концепции своими словами, то можно будет запомнить чуть ли не 100% информации статьи чуть ли не на целую неделю. Тот же результат можно достичь, если прочитать статью и в конце всю ее себе пересказать. Вот почему во время интервальных повторений необходимо как можно больше фокусироваться на активном вспоминании. Кстати, когда человек выполняет практические задания, это тоже автоматически является формой активного вспоминания, ведь ты работаешь с ранее изученной информацией и это является частью причины того, почему практические упражнения так эффективны.
Ты, наверное, задаешься вопросом, зачем запоминать что‑то, если можно просто использовать ChatGPT для получения быстрого ответа.
Чем больше полезной информации ты усвоишь и запомнишь, тем легче тебе будет понимать ответы ChatGPT и, что самое важное, сохранять эти ответы в краткосрочной памяти в виде части решения задачи, над которой сейчас работаешь. Ты также будешь глубже понимать ответы ChatGPT и даже вспоминать идеи, которые не были упомянуты в ответе.
Учись параллельно
Лучше работать над изучением одних и тех же трех навыков каждый день по часу и сосредотачиваться на них пару недель подряд, чем уделять по 3 часа в день одному навыку в течение нескольких дней и затем переходить к следующему. Это один из важнейших принципов. Я понятия не имею, почему он работает, но не обязательно понимать, как что‑то работает, чтобы это делать и получать ощутимый результат. Попробуй поучиться так и будешь поражен скоростью освоения навыков.
Фокусируйся на основах до полного их освоения
В чем заключается разница между профессионалом и любителем? Профессионал очень хорошо знает основы. Основы служат фундаментом для последующих тем, изучаемых в будущем. Например, чтобы быстрее освоить React, нужно знать JavaScript, и чем лучше ты знаешь этот язык, тем легче будет разобраться в React. Поэтому не торопись и досконально изучи компетенции, служащие основой для других компетенций.
Учись каждый день
После месяца обучения результаты будут намного лучше, если учить предмет по часу каждый день, нежели чем если учить его 7 часов в день раз в неделю. Это банально объясняется принципом работы интервальных повторений.
Начинай каждый день с 10 минут вспоминания того, что учил вчера
Утром, перед началом нового дня, удели 10 минут, чтобы вспомнить все, что учил вчера. Это очень эффективно, так как первое повторение в течение первых 24 часов после изучения темы имеет огромный эффект на запоминание.
Секретный ингредиент
Теперь у тебя есть основные принципы создания плана обучения, но что насчет секретного ингредиента? Хотя все вышеперечисленные пункты идеально подходят для эффективного долгосрочного обучения, если ты стремишься получить работу, твоя цель не в том, чтобы изучить как можно больше всего, а в том, чтобы достичь уровня, где у тебя есть крутые проекты и ты можешь успешно пройти собеседование. В этом случае секретный ингредиент — интенсивность. Например: чтобы достичь такого же уровня навыков в программировании, который тебе нужен для успешного прохождения собеса, ты можешь либо потратить 1000 часов за полгода, либо 1500 часов за год. Заметили разницу? За 1000 часов достигается тот же результат, что и за 1500 часов. Это объясняется принципом работы интервальных повторений: чем больше проходит дней, тем больше времени нужно тратить на интервальные повторения, в обратном случае информация просто забудется. Поэтому если сжать временное окно, в которое ты достигаешь необходимого уровня навыков, скажем, с года до полу года, то таким образом можно значительно уменьшить общее количество часов, необходимых для достижения цели, и, следовательно, работать меньше, получая бОльшие результаты. Теперь ты знаешь, что должен включать твой план обучения.
Пример плана
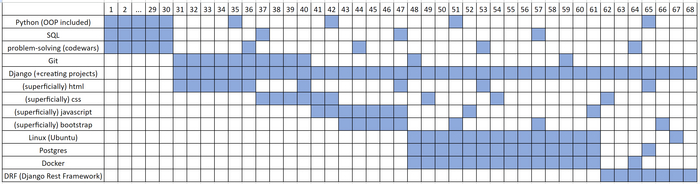
Давай теперь посмотрим, как может выглядеть такой план на примере реального плана становления python backend разработчиком:
Пример плана изучения python backend
Каждая колонка — это день, а каждая синяя ячейка — это как минимум 1 час сфокусированного базированного на практике обучения. Первый месяц ты параллельно учишь Python, SQL и алгосы (алгосы не в смысле заучки конкретных алгоритмов, а в смысле умения структурно думать и решать логичские задачки кодом, как, например, на codewars). Это то, что создает основу для всего остального, что ты будешь изучать. После этого добавляешь дни для вспоминания изученного, чтобы ничего не забыть. Далее начинаешь создавать проекты с использованием Django и подучивать немного фронтенд‑технологий, чтобы можно было потом показать рекрутеру хороший и красивый проект (хочешь работать беком? Учи фронтенд, чтоб тебя рекрутер не скипнул с твоими уродливыми проектами, понял да). Все это делаешь параллельно, а также учишь git для развития своего GitHub. Фокусируешься на создании проектов с Django до тех пор, пока не найдешь работу. Дополнительно добавляешь дни, в которые будешь повторять, что учил, чтобы ничего не забыть. Затем учишь параллельно Linux, PostgreSQL и Docker, завершая процесс изучением Django Rest Framework, одновременно повторяя все, что учил ранее. Как видишь, этот план включает в себя много практики, интервальных повторений и активного вспоминания. Ты учишь по нескольку предметов параллельно и сначала фокусируешься на основах. Ты учишься каждый день, начиная каждый день с 10 минут повторения того, что выучил вчера, что еще сильнее оптимизирует твое обучение. А занятия как минимум по 4 сфокусированных часа (а лучше — по 10) в день обеспечивают интенсивность, которая в полтора раза сокращает общее количество часов, необходимых на получение всех этих навыков.
Но как понять, какой конкретно курс проходить?
Короткий ответ состоит в том, что можно просто найти бесплатный курс и следовать ему, лично я предпочитаю использовать для этого YouTube. Бесплатные курсы обычно не содержат практических упражнений, являющихся самой важной частью обучения, поэтому упражнения на определенную тему придется отдельно искать в интернете. Или можно даже поступить еще лучше: когда смотришь курс и видишь пример кода, решающего конкретную проблему, попробуй придумать похожий код, решающий аналогичную проблему и поиграться с этим кодом в среде разработки. Это один из самых эффективных способов практики, который мне удалось найти.
Самое важное
Гарантирую, что, прочитав эту статью, ты потратил своё время зря, если не применил к ней вышеупомянутые принципы, так как забудешь все о чем я тут написал. Давай теперь объясню, как применить основные из этих принципов к любой статье или обучающему видео. Возьмем эту статью, например. Если ты проследуешь следующим нескольким шагам в течение следующих 5 минут, то это будут одни из самых полезных 5 минут в твоей жизни. Во‑первых, возьми свой телефон и скачай приложение под названием Anki Cards. Я не спонсирован этим приложением и не имею к нему никакого финансового отношения, поэтому у меня нет ссылки и тебе придется найти его самому. Шаг 2 — Перестань читать и прямо сейчас и попробуй вспомнить все, о чем я говорил. Объясни себе своими словами все, что удается вспомнить (да, прямо сейчас, я жду). Шаг 3. В зависимости от того, что удалось вспомнить, открой приложение Anki и создай несколько карточек об этой статье. Например: что такое интервальные повторения и как их применять? Что такое активное вспоминание? Какое лучшее соотношение между практикой и теорией для начинающих? Шаг 4. Сформируй привычку открывать это приложение время от времени, повторять карточки и добавлять новые о всем важном, что ты изучаешь в программировании. Лично я таким образом не только запомнил всё, что учил, но и ответил на 98% вопросов на своем первом в жизни собеседовании.
Есть такая проблема: у нас сенсорный монитор на работе, им нужно пользоваться, такая специфика. Программу для работы обновили, и появилась необходимость наводить курсор мыши на карточку товара, чтобы увидеть данные о нем. Но на сенсорном экране курсор мыши скрывается, и навести его невозможно, а значит, невозможно увидеть данные.
Кто-то знает, как на сенсорном экране заставить указатель мыши быть на экране ВСЕГДА?
СРАЗУ СКАЖУ:
Пробовали включить управление с клавиатуры. Указатель скрывается при нажатии. Настройки пера и сенсорного ввода: курсор не показывается. Настройки мыши и видимости курсора: не показывается. Настройки специальных возможностей: курсор все равно скрывается. Всё штатные способы перепробовал, при нажатии курсор скрывается.
И хорошо если пчелки правда знают о проблеме и работают над ее исправлением, но на деле чаще всего вы не видите даже этой ошибки, а просто ждёте бесконечный прогрессбар ... нет, прогрессбар - это про какой-то прогресс, процесс, с хотя бы отдалённо и приблизительно понятной продолжительностью.
Даже эти нехитрые технологии были потеряны
Отголоски развитой цивилизации и сейчас можно найти в виде скриншотов в сети:
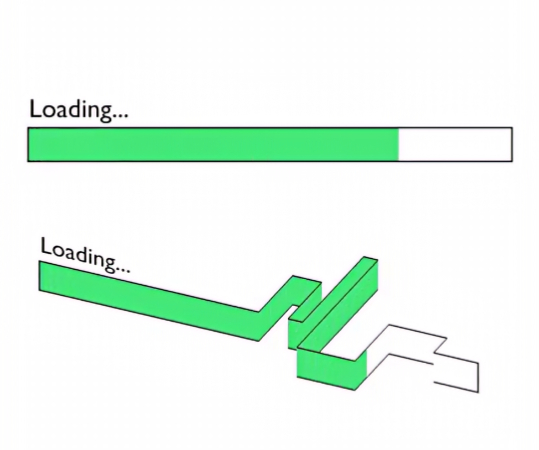
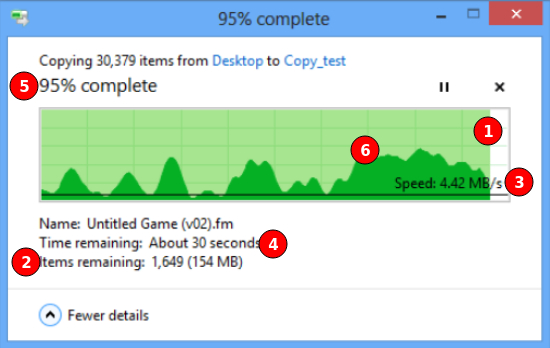
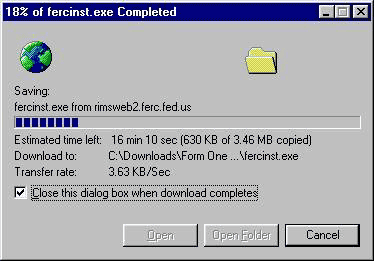
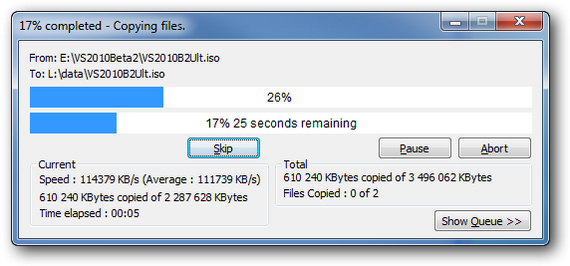
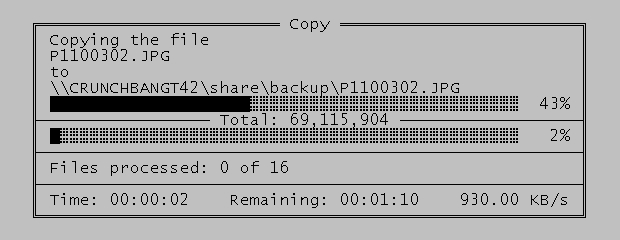
1/4
Что мы можем увидеть на прогресс-баре здорового человека
На хорошем прогресс-баре мы видим что, собственно, присходит, сколько элементов обрабатывается, общий процент выполненной работы (5), сколько примерно времени потребуется (4), сколько объектов и гигабайтов осталось обработать (2), скорость передачи данных (3), тот же процент но наглядно в виде заполнения бара (1) и даже график изменения скорости обработки данных!
Кстати, давно не пользуюсь windows, но, кажется, там сейчас такой или похожий прогресс-бар на копирование файлов, но...
Но во всех стальных местах где пользователю приходится ждать, его буквально заставляют СТРАДАТЬ!
Я не знаю кто это придумал, но уверен, что сам адский сатана его большой поклонник.
Установка программы, перезагрузка системы, ОБНОВЛЕНИЕ! Какого черта нигде не пишется даже сраный процент прогресса?! Порой вот эта тупая анимация просто крутится в виде зацикленной гифки, и она вообще никак не связана с процессом. Криворукие разработчики зачастую даже не думают потрудиться и сделать ожидание пользователя чуть более предсказуемым по времени и информативным.
Да ладно "по времени", иногда глядя на анимацию не понятно закончится этот процесс вообще когда-нибудь, или что-то там уже бесповоротно сломалось, а анимация эта бесконечная, на экране по-прежнему висит надпись "осталось совсем немножко, подождите, пожалуйста", и так ждать можно до тепловой смерти вселенной!
Неужели только меня одного бомбит от всего этого?
Сейчас придёт кто-нибудь в комменты защищать тугосерь-разработчиков, мол, ненуачо, ненуим манагер сказал так сделать, ненуакак они узнают сколько осталось, когда кампуктеры у всех разной производительности, интернет-соединение разное и, возможно, нестабильное, количественный прогресс может нелинейно зависеть от времени.
Ну так да, дорогие коллеги, в решении этих сложностей и заключается наша с вами профессия!
Ничего невозможного тут нет, а сделать лучше чем сейчас в 99% местах вообще не сложно.
Кто мешает эмпирически подобрать более адекватную кусочно-полиномиальную формулу аппроксимации? Кто мешает собрать статистику у контрольной выборки пользователей и выявить закономерности длительностей разных этапов процесса от примерного уровня оборудования? Кто мешает в ходе самого прогресса замерять скорость тех или иных операций, чтобы предсказать общее время процедуры. Хотя бы очень приблизительно. Хотя бы оценкой сверху "если ничего непредвиденного и редкого не случится".
Кто-то скажет, что, мол, радуйтесь, что вот, к примеру, при загрузке системы вам хоть анимацию с приятной картинкой показываем, а так вообще черный экран был бы. Ведь как пробросишь подробности процесса в тупой фронтенд? А так и пробросишь! Чуть поострее сделать фронт, чуть больше интроспекции, немного статистики и, вуа-ля, у вас дружелюбный информативный интерфейс, а не вот это вот вращающееся бесконечное говно на палочке.
И напоследок. Не надо считать пользователя идиотом, но и оставлять наедине со своими проблемами без какой-либо информации - тоже не надо. Правильная обработка handled и unhandled исключений изучается в институте, но это не рокет-сайнс, тут можно освоить базовые премудрости.
Пользователю должно быть понятно, что что-то пошло не так, ему должно быть понятно имеет ли смысл и имеется ли возможность решать как-то возникшую проблему, или стоит сразу в ужасе удалить поделку неграмотных "погромистов", чтобы не терять время и искать уже более качественный софт.
Винда, кстати, тоже не безгрешная, в плане наплевательства на удобство пользователя при ожидании. Чего стоит только вот это вот внезапное желание обновиться. Сколько было случаев, когда винде (и не только) приспичило срочно обновиться, когда горят сроки и нужно доделать курсовую, или срочно надо распечатать документы, или быстро скопировать нужный файл, или целая аудитория ждёт презентации на подключенном к проектору ноутбуке...
21 век на дворе! Пора делать все эти побочные процессы, которые не нужны, по сути, пользователю, просто незаметными и НИКАК не затрагивающими пользовательский опыт.
Пора писать софт везде так, как это делали для Вояджеров и марсоходов. Предсказуемо, конфигурируемо, надёжно. Что стоит при обновлении делать равнозначный клон ядра операционной системы и обновлять его, а не работающю систему? Потом "щёлк" и у вас обновленный софт! Что мешает? Техническая сложность? Ну так пора сделать это важным техническим преимуществом, чтобы была конкуренция за такое удобство.
Простите, друзья, что-то меня подорвало снизу. Отбомбил. Думаю эта статья уже малость припоздала лет эдак на 10. Сейчас проблема, может быть, уже стоит не так остро, компы у нас быстрые, каналы широкие, нервы правда ни к черту, ну да что поделаешь...
Картинки для иллюстрации взяты из сети, а эмоции из глубин воспалённого мозга.